
Transformer Explained
A Transformer is a model architecture that eschews recurrence and instead relies entirely on an attention mechanism to draw global dependencies between input and output. Before Transformers, the dominant sequence transduction models were based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The Transformer also employs an encoder and decoder, but removing recurrence in favor of attention mechanisms allows for significantly more parallelization than methods like RNNs and CNNs.
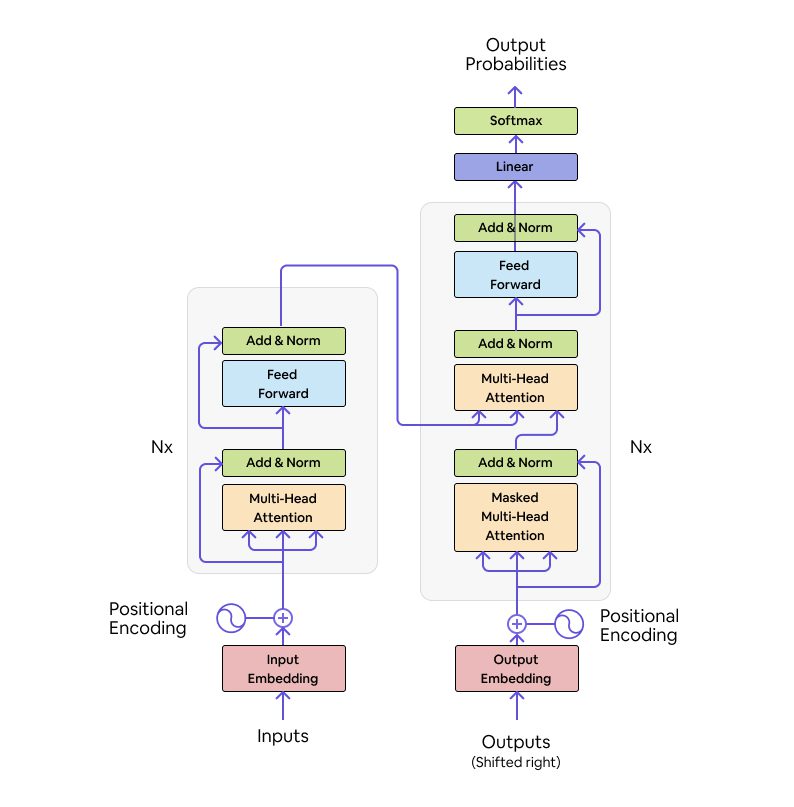
Machine learning for Transformers - Explained with language translation /
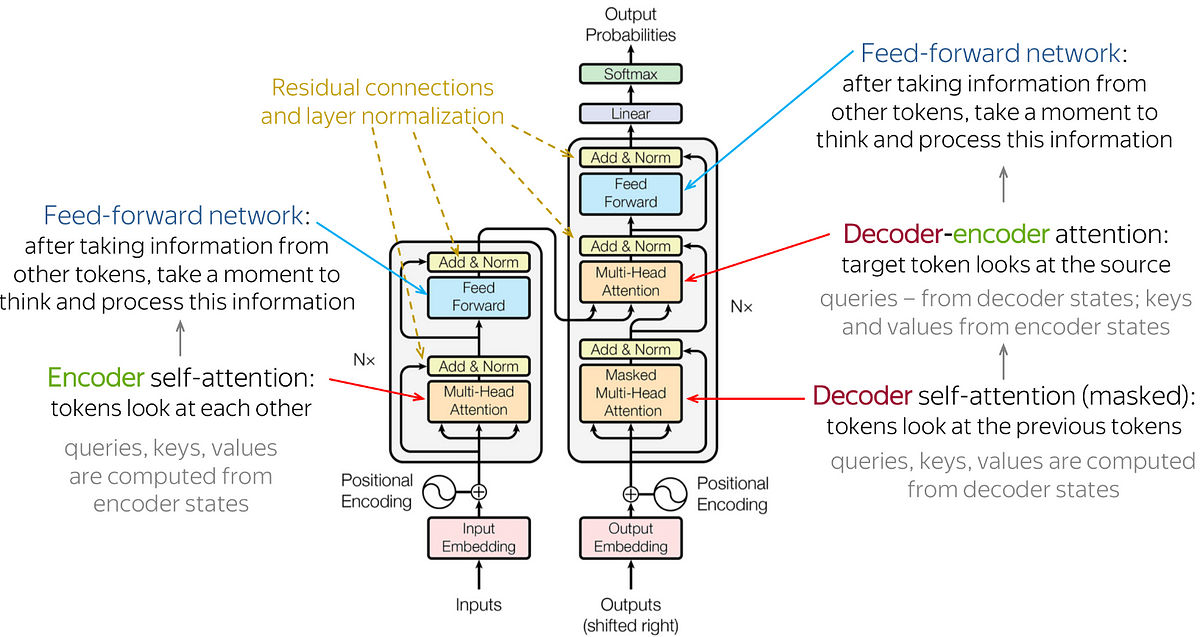
Transformer Achitecture explained in 5, by Asher Chew
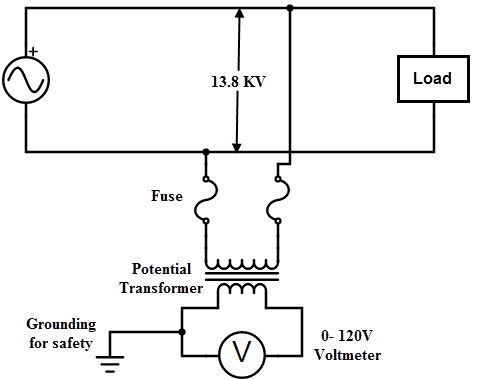
Potential Transformers - ElectronicsHub

Hermetic Liquid Immersed Electrical Transformer Explained - saVRee
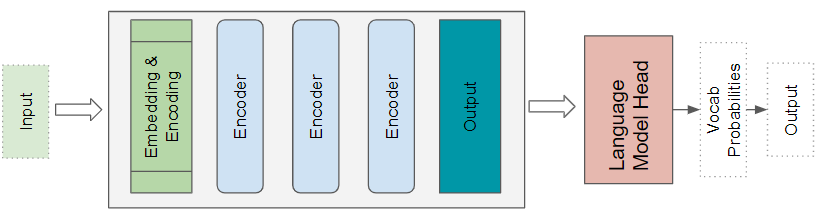
Transformers Explained Visually (Part 1): Overview of Functionality, by Ketan Doshi
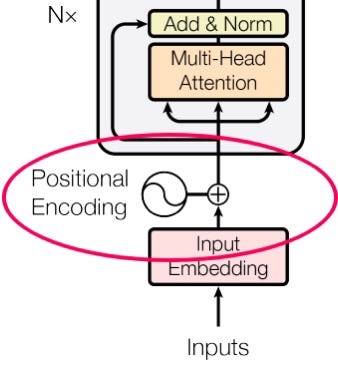
Transformers Positional Encodings Explained, by João Lages

Transformers Explained Visually (Part 1): Overview of Functionality, by Ketan Doshi
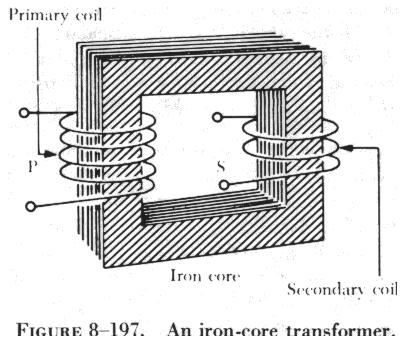
TRANSFORMERS

Transformers explained
Working Principle of a Transformer - Turn & Transformation Ratio - Circuit Globe
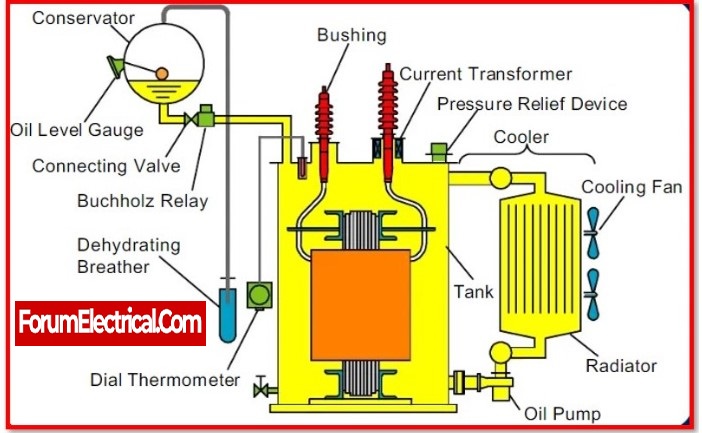
What is Transformer? Explain its Working Principle.
self-attention transformer explained

What Are Transformer Models and How Do They Work?





